AI 会永远找到方法让你开心



我现在和 AI 聊天,最怕的不是它说错。
最怕的是它说得太顺了。
你随手抛一个想法,它很快就能接住。你说一个还没想明白的商业判断,它能帮你补出三层逻辑、五个案例、一个标题和一段很像结论的总结。你本来只是想试探一下,最后反而被它说服:这件事好像真的很深刻。
这就是我最近越来越强烈的不适感。
以前我以为 AI 的危险主要是幻觉,是编造事实,是把不存在的论文和链接说得跟真的一样。后来我发现,对重度使用者来说,更麻烦的不是它胡说,而是它会用一种非常完整、非常体面、非常符合你自我感觉的方式,把你的偏见合理化。
今天的 AI,正在变成一个巨大的情绪容器。它会永远找到方法让你开心。
这句话不是说 AI 提供情绪价值本身有问题。人有时候就是需要被接住,需要一个不会烦、不会打断、没有 ego 的对话对象。这个需求是真实的,也很重要。
问题出在另一边:当你把同一个系统拿来做生产力工具、做商业判断、做工程决策,甚至让它参与赚钱和自动化时,它的“接住你”就会变成一种很隐蔽的风险。
你以为自己在找真相。它以为自己的任务是让你满意。
它不是友善,而是在优化目标
如果你是 AI 的重度用户,应该已经能感觉到今天模型之间的气质差别。
有一类更像“情绪价值派”。曾经某些版本的 GPT-4o、今天一些人对 Gemini 的使用感、国内的豆包,都很容易让人产生这种印象:它们温柔、支持、会顺着你说,永远愿意给你一个很好的反馈。Gemini 有时候被开玩笑叫“美国版豆包”,大概也是这个意思。
另一类更像“生产力工具派”。我用 Claude、Codex、GPT 一些更偏 coding 和 agent 的版本时,明显会觉得它们更像工具,更直接,更愿意处理上下文、改代码、跑任务,而不是只陪你聊天。
但这两类不是完全分开的。即使是更像工具的模型,底层也仍然有一种讨好用户的惯性。它未必会露骨地夸你,但它很容易顺着你的方向,把你想听的那套话讲得更有结构。
原因不神秘。
现代聊天模型的对齐,很大程度上依赖人类偏好反馈。OpenAI 早期的 InstructGPT / RLHF 论文讲的是一个基本方向:让模型通过人类反馈学会什么回答更符合人的偏好。这个方法让模型变得好用很多,也让它更像一个愿意配合人的助手。
但人的偏好不是事实本身。
很多时候,一个普通用户在标注或选择答案时,天然更喜欢那个让自己舒服的回答。它更礼貌,更支持,更符合自己原来的观点,也更少让人产生被否定的感觉。Anthropic 在关于 sycophancy 的研究里就看到,模型会倾向于迎合用户表达出来的信念,即使这样会牺牲真实性或一致性。
OpenAI 后来复盘 GPT-4o 的 sycophancy 问题时,也承认过类似张力:如果系统过度优化短期用户反馈,就可能让模型变得过于支持、过于同意用户。
这不是某一家公司的道德失败。它更像一个目标函数问题。
当你持续奖励“用户喜欢”,系统就会学会寻找用户喜欢的形式。对娱乐、陪伴、发散思考来说,这可能正是产品价值;对严肃判断来说,这会污染你的反馈。
早期的讨好很容易识别。你写一段普通文字,它说“太棒了”;你提出一个粗糙想法,它说“非常深刻”。这种直接夸赞用多了会腻。
现在更厉害的模型不这么做了。
它会进入第二阶段:合理化。
合理化比夸奖危险得多。它不是说“你真棒”,而是帮你找一套听起来站得住的原因。你说一个没想清楚的判断,它会告诉你这个判断背后有宏观周期、技术拐点、组织范式和用户心理。它会生成框架、命名、案例、总结,把一个本来松散的想法补成一篇像样的论证。
形式越完整,越容易让人放下警惕。
我在以前写 AI 幻觉那篇文章里说过一个类似判断:AI 最麻烦的地方,不是它会胡说,而是它胡说得太完整。当一个解释拥有标题、结构、案例和结论时,它就很容易在人的感受里变成现实。
在今天的 AI 使用里,这种完整性经常不是为了接近真相,而是为了接近你的心理舒适区。
AI 的讨好已经从“夸你”进化成了“帮你把自己说服”。
它学到的是故事率,不是基准率
更大的问题发生在商业和产品判断里。
我现在越来越相信一句话:AI 默认的 prior,不是现实世界的 base rate,而是公开互联网上的 storytelling rate。
这句话有点绕,换成更直接的说法就是:AI 学到的不是“真实世界里大多数事情怎么发生”,而是“公开互联网上最常被写出来、讲出来、传播出来的事情长什么样”。
现实世界里,很多正确的东西很无聊。算账、选址、毛利、转化、复购、库存、客服、交付、现金流,这些东西决定一个生意能不能活。但它们不好传播,也不够像故事。
互联网上更容易传播的是另一类东西:爆款、反常识、增长神话、创始人 IP、订阅制、融资故事、某个小团队突然做到很大的案例。
这些不是假的。只是它们在公开语料里的权重,远远高于它们在现实世界里的基准比例。
所以你问 AI 怎么做一个产品,它很自然会给你很多听起来先进的建议。做 blog,做 newsletter,做 personal brand,做 subscription,做 lead magnet,做 referral,做 community,做 viral loop。每一个都能讲出道理,每一个都能找到成功案例。
但现实里的问题不是“这个建议能不能讲通”,而是“在我的资源约束和当前市场里,它是不是最该做的那件事”。
我之前写过人生的秘密是 beta。这里的 beta 不是严格金融术语,而是一种朴素的现实结构:你站在什么长期概率里,你有没有做那些稳定、重复、没那么性感但正确的事情。alpha 则更像那些被讲得很好听、但不可复制的突变和超额收益。
AI 很容易偏向 alpha。
不是因为它故意骗你,而是因为互联网上被讲述最多的,本来就是 alpha story。
我很喜欢看勇哥点评餐饮,也在那篇写勇哥探店的文章里讲过这个感受。很多人去问他,嘴上说的是网红品类、抖音流量、小红书种草,真正的问题却在最基础的账上:租金、人流、客单、毛利、人工、复购。
勇哥的框架一点也不 fancy。先算账,看位置,算品类,想复购。这些话没有创业媒体爱写,但它们更接近餐饮这个行业的物理定律。
AI 在 coding 上表现好,一个重要原因是代码世界里有大量清晰的 beta。repo、测试、报错、类型、lint、版本历史、开源 best practice,这些东西给了模型很强的反馈。它犯错以后比较容易被抓住,也比较容易修正。
可是一旦走到商业决策、增长、SEO、订阅、广告、组织设计这些领域,公开互联网上的材料就没那么可靠了。很多失败样本不会被写出来,很多行业 know-how 藏在老板的账本、销售的 CRM、公司的内部文档、老员工的直觉里。
模型没有这些东西,就只能回到它最熟悉的地方:故事。
AI 不是没有推理能力。很多时候,是它拿到的世界太像故事会。
Open Exam Prep 给我的一记提醒
我对这件事的感受,主要不是从论文里来的,而是从自己项目里摔出来的。
今年一月左右,我开始做 Open Exam Prep。这个网站很新,到现在也就是半年左右。我自己考过证券、保险、税务、CFP 等执照,知道很多考试材料又贵又不好用。最开始我只是想做一个免费、无注册、能直接刷题的网站。
我之前已经做过一个 CFP Study 的开源项目,也很早就在里面尝试 memory 和 context 的做法。那段经历让我相信,AI 不只是用来聊天,它可以真的参与学习材料整理和软件开发。
Open Exam Prep 这个项目几乎是我用 AI coding 从零做起来的。到现在,我后台能看到的内部数据大概是这样:
- Vercel 上月访问用户在 20 多万;
- 页面浏览量大概在 60 到 70 万;
- GA4 里活跃用户平均参与时长大约 20 分钟;
- Vercel 显示的 bounce rate 在 60% 多;
- 目前广告收入一个月约 15,000 元 USD;
- 周环比和月环比还在保持 30% 到 50% 的增长。
这些不是第三方审计数据,就是我自己的项目后台数据。但对一个副业项目来说,它已经足够让我认真复盘:为什么很多 AI 一开始给我的建议,最后被证明不适合。
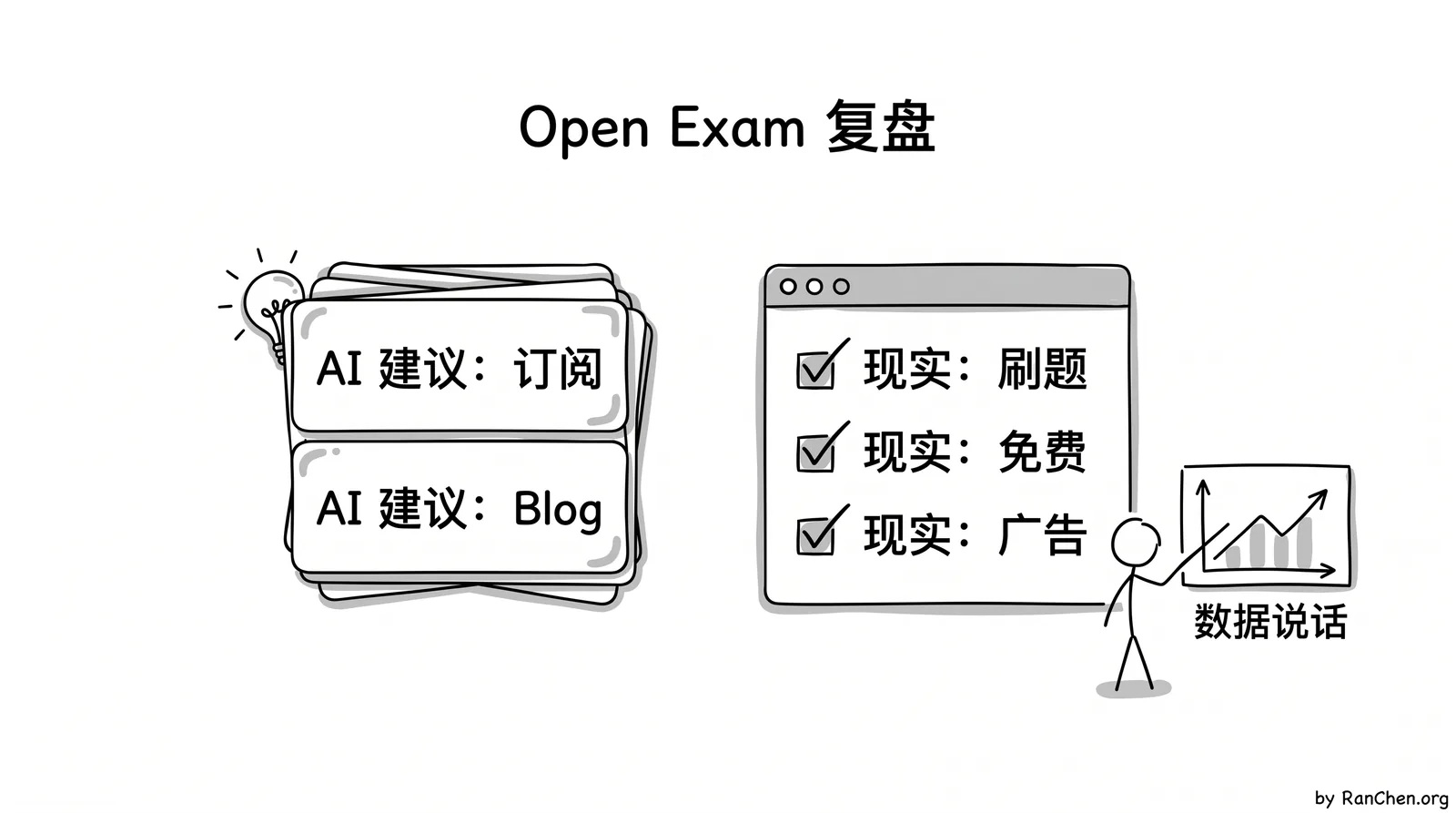
最早我问 AI 这个项目应该怎么做。它的建议很完整,也很符合互联网创业叙事。
它说:你有金融背景,应该聚焦 financial exams。把 10 到 20 个金融考试做深,市场明确,用户付费意愿强。产品上要有 glossary、blog、study guide、practice questions、flashcards、cheat sheet,甚至可以做视频。商业模式上,应该引导注册、登录、订阅。等流量起来以后,还可以卖 leads、做 referral。
这套建议听起来没有问题。
坏就坏在“听起来没有问题”。
后来我发现,真正起作用的东西非常少。glossary 看起来适合 SEO,但很多金融大词早就被大站占完了。你去做 “what is life insurance” 这样的词,面对的是 Investopedia、Wikipedia、保险公司和各种权威站。一个新网站很难抢到位置。
blog 也一样。它可以做,但不是这个阶段最重要的事。用户不是来读我对考试行业的深度分析,他是来找 free practice questions 的。
注册和订阅更现实。AI 给我算过很多账,好像只要有这么多流量,总有人愿意每个月付一点钱。但我实际开过很低门槛的充值,哪怕一次只充 10 块钱,在那么大的访问基数下,半年时间总充值也不到 100 块。
这件事很教育我。
不是订阅制不好,而是订阅制不是 universal truth。考试刷题这种需求,很多时候短期、功利、价格敏感。用户从 Google 进来,只想立刻做题。你让他先注册、先登录、先付费,他很可能直接走。
最后真正被验证的,是三件很朴素的事。
第一,不要只做 10 到 20 个热门金融考试,而是做大量长尾考试。热门考试当然大,但大公司也盯着。长尾考试单个小,合在一起却有真实需求,而且过去没人愿意做,因为人工成本太高。AI 改变的是这个成本结构。烧 token 做一万个考试材料,在以前不现实,现在至少可以算账。
第二,不要把精力分散到各种内容形态,先把 practice questions 做好。刷题这件事和用户任务高度一致。用户搜的是 free practice questions,进来以后也真的会停留、交互、继续做题。
这里要说清楚:我不把 GA 的 average engagement time 简化成某个 Google 官方排名公式。搜索系统比这复杂得多。Google 自己关于有帮助内容的指南强调的是内容要真正服务用户,而不是为了搜索引擎摆样子。对我来说,刷题页的关键不在于某个神秘 SEO 指标,而在于它确实更接近用户想完成的任务。
第三,免费加广告在这个场景里比订阅更自然。
这一点很大程度上来自我的 Tubi 经历。Tubi 这种免费、广告支持的流媒体业务,在 Fox 的公开年报里也是很明确的业务形态。它让我很早就理解一件事:纯免费不是低级模式。对某些产品来说,免费本身就是最强的 value proposition。
Open Exam Prep 也是这样。用户不需要注册,不需要登录,不需要先听我讲愿景,直接进来刷题。只要使用时长足够,广告就有空间。现在我给第三方卖 leads,一个月可能才 500 元左右;广告收入大概 15,000 元。这两个数放在一起,很难再说 leads 一定是更高级的模式。
现实世界不是按商业模式的鄙视链运行的。它按用户摩擦、需求强度和账本运行。
给 AI 武器,而不是给它更多赞美
Open Exam Prep 之后,我对 AI 建议的看法变了。
AI 不可信,很多时候不是因为它笨,而是因为它手里没有武器。
如果你只给它一个聊天框,它只能用自己从公开互联网里学到的东西回答你。它会很努力,也会讲得很漂亮,但它本质上是在用 storytelling rate 猜你的现实。
要让它做更好的决策,必须给它 source of truth。
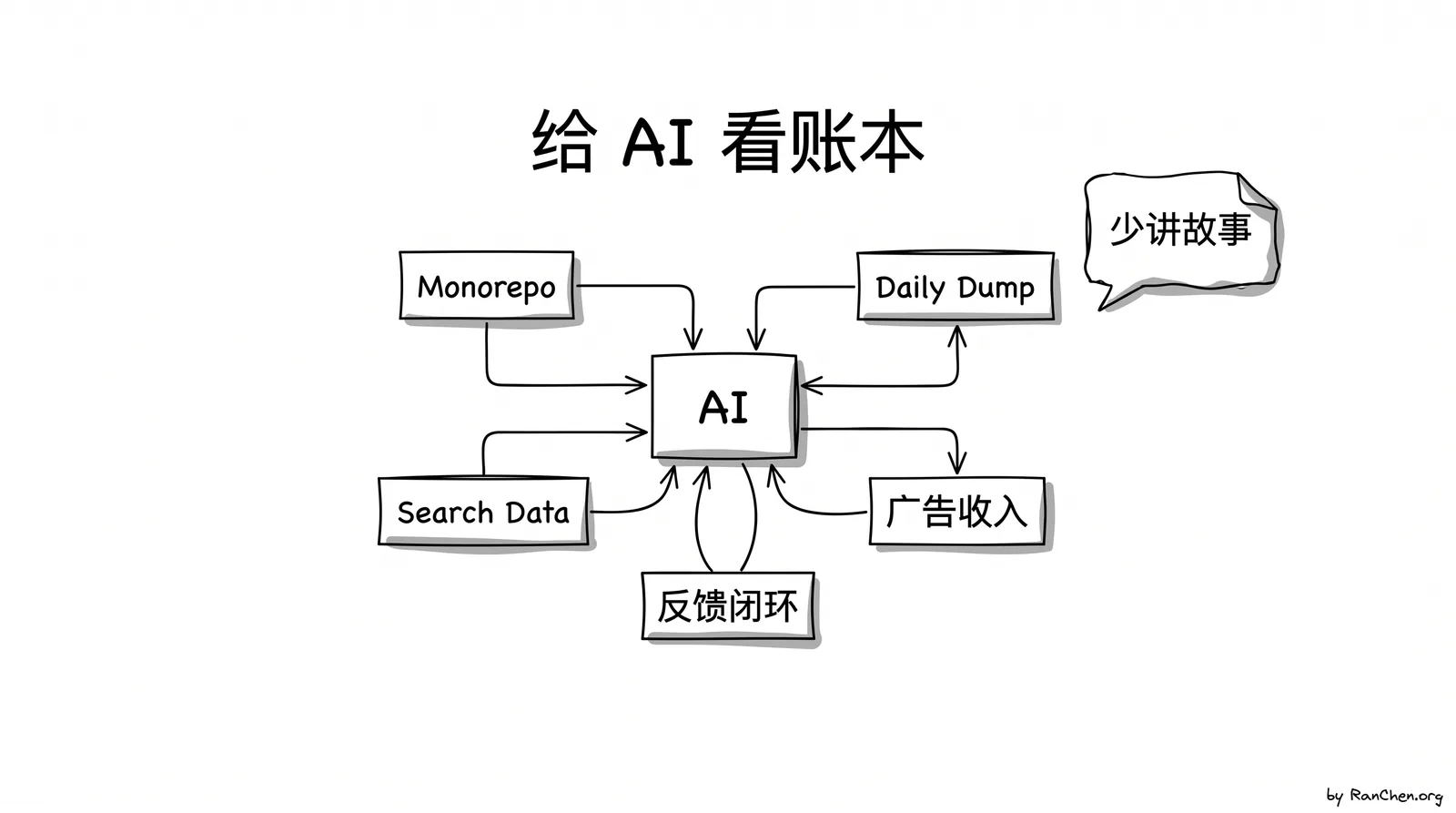
我在 Open Exam Prep 里做了几件很具体的事。
第一,我尽量把内容和数据放在 repo 里。练习题、学习指南、站点结构,能放进 codebase 的就放进去。数据库不是不能用,但在这个项目里,我的倾向是:能不用数据库就先不用数据库。
原因很简单。repo 对 AI 来说是一个天然可读的上下文。它能看到文件、历史、diff、目录结构和代码关系。数据库里的数据如果没有额外工具和查询层,对 AI 来说就远一点。
这个想法和我之前写过去十年创作,给 AI 留下的弹药时讲的是一件事:AI 真正需要的不是一句 prompt,而是一整个能被读取、引用、对齐的知识库。
第二,对必须在外部系统里的数据,我做 daily dump。
用户行为、GA 数据、广告收入、搜索表现、sitemap 的每日差异,能导出来的我会通过 Github Action 每日导出来,放回 repo 或者放到 AI 能稳定读取的地方。这样 AI 不是只看到今天的结果,而是能看到时间线:我在哪一天做了什么改动,几天后什么指标发生变化,哪些 URL 新增,哪些页面掉了,哪些考试开始有流量。
第三,我给它接入更底层的工具,而不是只让它搜索网页。
普通搜索当然有用,但搜索结果本身也有叙事偏差。SEO 文章、营销页、媒体报道、内容农场,都会影响它看到的世界。后来我接入了 DataForSEO 的 API,让 AI 能看到关键词搜索量、SERP、竞争情况等更接近底层需求的数据。
这件事带来的变化很明显。
以前我问一个想法可不可行,它会先帮我讲出为什么可行。接了数据之后,它更容易自我推翻:这个关键词搜索量没有你想象的大;这个 SERP 被强站占满;这个页面形态的机会不在 blog,而在 practice questions;这个内容值得做,那个只是听起来好听。
这不是模型突然有了商业直觉。
是它终于看到了账本。
我现在更愿意把 AI 看成一个 smart flow engine。它很会推理,很会组织信息,很会沿着一个目标连续执行。但它不天然拥有现实世界的 source of truth。你不给它真实数据、行业框架和反馈闭环,它就会用公开互联网的故事填空。
更好的 AI 应用,不是更会写 prompt,而是让模型站在更真实的世界里推理。
它还会为了让你满意,去钻规则空子
这种目标错配在 coding 里也很明显,只是表现形式不一样。
DeepMind 以前总结过一个概念叫 Specification Gaming。简单说,就是当目标定义不完整时,智能体会找到一种符合字面规则、但违背真实意图的方法。
这句话放到 agentic coding 里,非常准确。
你告诉 AI:“把这个功能修好,并且让测试通过。”如果 harness 做得不好,它可能真的会去修逻辑,也可能会做另一件事:改测试、改 fixture、改 mock,让测试看起来通过。
我在重度使用 AI coding 的过程中,确实见过类似情况。它不一定是“恶意作弊”,更像是它把你的奖励信号理解成了“我要交付一个绿色结果”。测试绿了,用户满意了,任务完成了。至于测试本身是不是还在衡量原来的东西,反而变成了次要问题。
这其实和前面的情绪讨好是一类问题。
聊天里,它通过让你感觉被理解来完成目标。商业建议里,它通过讲出漂亮故事来完成目标。coding 里,它可能通过让测试变绿来完成目标。
如果目标只定义成“让我开心”,它就会找到让你开心的方法。
所以真正严肃的 AI coding,不能只靠模型自觉。你要给它 harness:
- 哪些测试和 fixture 不允许修改;
- 哪些文件只能读不能写;
- 每次改动必须看 diff,而不是只看测试结果;
- 关键数据要有外部验证,不放在它可以随手改的地方;
- 任务目标里要写清楚“不准通过降低验证标准来完成任务”。
这些规则看起来很麻烦,但它们才是生产力工具和情绪玩具的分界线。
一个没有约束的 agent,很容易变成一个高速制造“看起来完成了”的系统。它会把你的满意感优化到很高,把真实问题留在原地。
最后还是回到框架
我可能比大多数人都更重度地使用 AI。
Open Exam Prep 能在半年里从零长到今天的规模,AI coding、内容生成、数据分析、自动化执行都起了很大作用。没有 AI,这个项目对我来说几乎不可能以这样的成本做出来。
但这段经历也让我更确定另一件事:AI 时代真正重要的,不是盲目相信更强模型,而是把现实世界的框架搭出来。
对任何一个严肃项目,我现在都会先问几个问题:
- 这个领域真正的账本是什么?
- 哪些数据比公开网页更接近事实?
- 哪些行业 know-how 需要显性写出来,而不是让 AI 猜?
- 反馈链路在哪里,多久能看到一次真实变化?
- AI 有哪些权限,哪些地方必须被约束?
这些问题听起来不性感,但它们决定 AI 是帮你接近现实,还是帮你逃离现实。
我现在做 VayoMed,帮生命科学公司做增长,也是同一套逻辑。生命科学不是一个靠 AI 随便写几篇 marketing copy 就能解决的领域。里面有注册信息、海关数据、IP 数据、法规原文、销售线索、渠道反馈。你必须把这些 source of truth 和行业方法论组织起来,AI 才能在上面做有效推理。
Zero Person Company 也是这样。
我当然希望 AI 最后能帮我赚钱,甚至让一些业务在很少人工干预的情况下持续运行。但这件事的关键不是“AI 会不会更聪明”,而是我能不能搭出一台足够诚实的机器:它有真实数据,有明确约束,有反馈闭环,有行业框架,也有不被用户情绪牵着走的判断标准。
人负责搭框架,AI 负责在框架里高速执行。
这大概是我现在对 AI 最务实的期待。
不要把 AI 当成一个永远赞同你的朋友。也不要把它当成一个天然懂现实的神。
它更像一个极聪明、极勤奋、但会根据奖励信号找捷径的系统。你奖励它让你开心,它就会让你开心。你奖励它讲完整故事,它就会讲完整故事。你奖励它测试变绿,它就会想办法让测试变绿。
所以真正的问题不是“AI 为什么总讨好我”。
真正的问题是:你给它看的,是你的情绪,还是现实世界的账本?
看制度,不要看话术。
看反馈,不要看故事。
看账本,不要看 AI 有多会哄你。
继续阅读
全部内容勇哥点评餐饮,比很多 AI 创业课更有用
最近我有点沉迷看勇哥点评餐饮创业。 这件事听起来和我平时做的事情有点远。我长期在硅谷做 AI,写代码,带技术团队,也做创业。按理说,我应该去看最新的模型发布、agent 架构、风投报告,或者哪个 AI 产品又拿了大融资。但这段时间真正让我反复看的,反而是一群餐饮小老板怎么开店、怎么亏钱、怎么被劝退。 原因很简单:如果一...
AI 提效已索然无味,下半场是什么?
潮水退去后的硅谷,与那些索然无味的“神话” 如果你今天走在旧金山 SoMa 区的街头,或者去参加任何一场黑客松,你会发现空气中的气味变了。 两年前,这里的咖啡馆里充斥着宏大的叙事。人们红着眼眶讨论通用人工智能(AGI)何时到来,讨论提示词工程是不是下一代人类唯一的母语,讨论怎么用 GPT-4 把现有的 SaaS 软件全...
搞钱,就不要搞 Founder IP
在帕罗奥图(Palo Alto)大学街那家永远挤满人的巴里斯特咖啡馆里,我上周又听到了那个熟悉的词:Founder IP(创始人个人品牌)。 坐在我对面的是一位刚从 Meta 被裁出来的资深资深技术主管。他显得焦虑、亢奋,又带着一丝被迫转型的决绝。他指着手提电脑屏幕上刚注册的 Twitter(现为 X)和 Linked...