[ML 1分钟]细节太多,犯错太容易


机器学习工程师小月最近一直在研究新的深度学习算法。相对于现有的算法框架,新算法要求兄弟团队一块搭建了不少新的框架,也选用了一些以前不太熟悉的库。经过了三个月的准备,终于可以上线AB测试了。
但是AB测试效果老是不好

经过了几个月的迭代,效果依然不佳,仅仅只比手动排序更好,与现有的模型相比效果差距甚远。离线数据 AUC,NDCG 也都还不错,但是一到 AB 测试效果就不好。
小月很沮丧,苦恼地去找经理大圆。想让经理帮忙看看是不是算法选择的不好,是不是应该再试试不同目标函数或者超参数。
经理曾经也是很资深的工程师,遇到这种情况不慌不忙。毕竟线下结果好,但是线上结果不好的情况也很常见,但是在这之前,模型的优化并不是最重要的,首先要确保的是系统运行与预期相符。
年轻的工程师们都喜欢高大上的东西,觉得那才是未来。但越资深越知道魔鬼都在细节之中,细节对了结果才会对,出结果了才是他好我也好。
搭建测试环境
首先要搭建出好的测试环境。一个常见的实时预测模型如下图所示,其中的哪一个地方都有可能出问题。
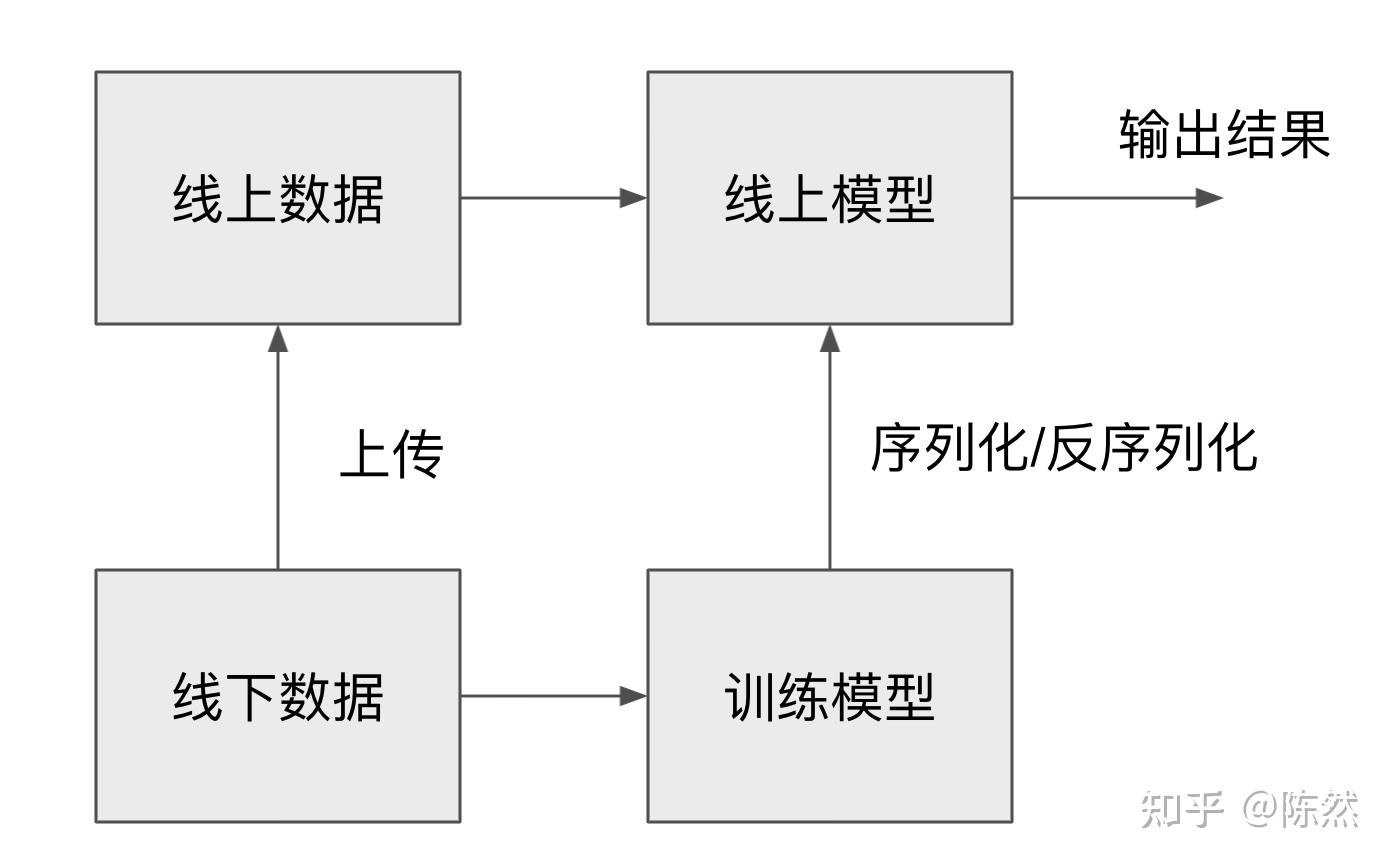
先要隔离出哪里可能出了问题:
- 线上数据和线下数据是否一致
- 线上模型和线下模型是否一致
- 线下模型调用线上数据得出的结果是否跟调用线下数据一致
- 线上/下模型调用线上/下数据的方法、列名称等等是否一致
一个好的离线测试环境可以灵活地搭配线上下数据和模型的各种组合,快速发现问题在哪里。
问题很多
小月与经理一块联调了多个系统,还真发现了不少问题:
- 线上线下的数据不一致,核心的问题是数据管道中对于 date 这个参数的处理,到底是数据ETL 任务发生的时间,还是实际数据的时间,在不同的函数和任务中的意义不同,导致经常有错开一天的问题,这个问题广泛存在。
- 隐式精度转换的问题,导致 Double 与 Float 被隐式转换了丢失了精度。这一点有可能发生在很多地方,比如线下数据传给线上数据库中,中间的中间件自动转换了数据的精度。再比如线上的模型的服务,在反序列化后也隐式地转化了数据的精度。这都可能造成数据的不统一。
- Null 数据的处理。不同的数据库,数据中间件,模型都对于 Null 的处理不同,有的会保留 Null,有的填充为空字符串,有的填充为0,有的还甚至填充为“NULL”字符串。为了解决这个问题,所有的数据都应该显式地填充。
在修改了若干工程上的问题后,小月终于可以确保模型的输出与预期一致了。他现在也养成了个好习惯,不管模型是什么,一定要确保每一个步骤都去看:模型、线上服务、线下数据管道,只有每一个细节都与自己的预期一致了,才敢放心大胆地上线实验。
细节太多,犯错太容易
机器学习模型看起来不复杂,但是依赖的系统太多,出错的概率非常高。一个不成熟的团队,50%以上的AB测试,事后都会发现其实是有工程上的问题,而导致试验结果不准确的。
而作为一个机器学习工程师,当然要对线上的结果负责,算法上的东西其实好学,但是工程能力反而是人和人最大的差距。
继续阅读
全部内容大模型落地的未来:开源+微调?
最近,AI 社区里流传着这样一句话——“通用大模型很强,但我并不需要我的应用去给我背诵法文诗歌。” 这句话听上去有点调侃,却反映了一个重要现象:许多企业和开发者在早期会选择大型通用模型(例如 GPT-4)去快速验证想法,但真正想要落地到生产环境,往往发现必须在速度、成本和“专用领域准确度”之间做权衡。 于是,“微调(F...
[ML 1分钟]第一个模型能跑通就不错了
有业务能上机器学习模型了,算法工程师小月开心地不行。毕竟作为一名机器学习工程师,口袋子藏着无数陈年老模型:线性模型、树模型、深度模型、增强学习,要啥有啥。业务一来,恨不得立刻就掏出最炫酷的模型,一步到位。 但是,第一个模型,一定要简单 正当小月兴奋着呢,经理大圆泼了一瓢冷水,“第一个模型,一定要简单”。 第一个次迭代往...

[ML 1分钟]第一版排序不上机器学习算法
一个新的产品需求来了,产品经理总会提前很久就来找机器学习的团队,讨论能不能在第一版上线中就加入“神奇的”机器学习排序算法。 “我也是想呢,但是不行“。 我们当然想着用机器学习去帮助每一个产品,但是在实践中,最早的版本不应该考虑机器学习算法。 原因 背后的原因有很多。 第一当然是数据。不管是有监督还是无监督算法,或多或少...