推荐系统有哪些坑?


最近在团队分享了旅游网站 Booking 在 KDD 2019 年的文章150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com,里面提到了一些有意思的“坑”,分享一下。
Booking.com 网站界面
线上线下结果不一致
做机器学习模型一定都会计算各种线下的模型,比如根据历史数据计算在训练集上的 CTR 和在测试集合上的 CTR。但是线上的指标我们往往看的都是业务指标,比如流媒体就会更关注观看时长。Booking 发现,线下的模型指标和线上的业务指标几乎没有任何相关性。
首先要退一步说,这里的对比不是线上线下的模型指标,换句话说,就算线上的 CTR 提升了,但是观看时长并不一定提升。
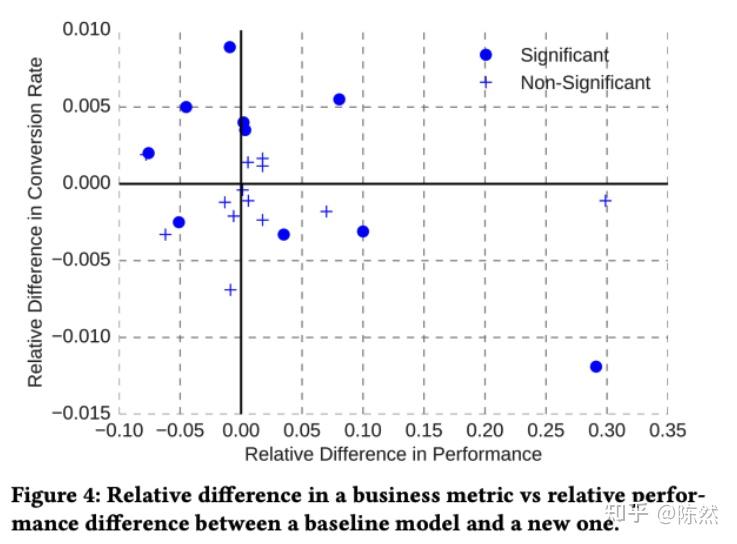
线下的模型指标和线上的业务指标几乎没有任何相关性
Booking 提出了几种可能的原因:
- 过度优化:当模型已经被优化了很多次之后,再提升的空间已经很小了,在当前的 AB 测试框架中可能已经检测不出来了。
- 恐怖谷效应:过好的推荐结果甚至可能让人感觉害怕。在下图的例子中,用户仅仅输入了Salzbug 和 London 之后网站就猜测他需要在 Vienna 停留,这完全猜中了他的计划,让他非常害怕,其他用户甚至建议他查看是否开启了麦克风,认为网站会偷听日常对话。但 Booking 说这仅仅是一个马尔可夫模型的推荐而已。
- 过度优化替代目标:我们线上的业务指标更多的是类似于观看时长,而线下很难直接对其优化,所以往往选用替代的 CTR。但过度优化也可能会带来反效果,反而不利于线上业务指标的增长。
还有一点 Booking 没有提但是很常见的就是 Presentation Bias。历史数据里面只有用户看到的数据,但是对于用户没有看到过的数据的真实互动情况我们并不知道。过拟合历史数据也并不一定是好事。
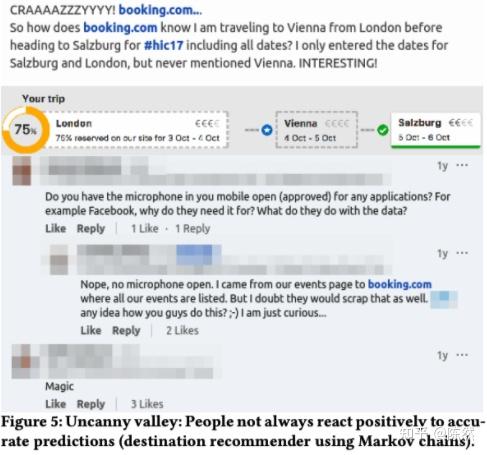
恐怖谷效应
这个问题几乎无解,最常见的方法就是不要过度沉迷线下优化,而加速迭代,多上实验。把线下指标只当作 health check。只要问题不大,还是应该在线上 AB 测试的框架中验证。所以一个公司一年能上多少 AB 测试是衡量这个公司数据驱动的文化的重要一环。作为参考,Tubi 大概10人主要做推荐算法大概一年上线实验的数量是 100+,这个数字还在快速上升。
业务指标不好可能不是模型的问题,而是建模的方式不对
很多时候我们试图用机器学习模型去提升一个业务指标,但是不管怎么优化,模型线下表现不错,但是线上的结果不好。这个时候的问题可能并不是模型本身,而是我们建模的角度不对。
事实上对于一个业务问题如何建模,本来就有很多种方式。比如 Booking 的例子是用户旅行日期灵活度模型(Date Flexibility Model),这个模型的目的是看用户对于日期的选择有多么灵活,这样在搜索的排序或者提醒中可以更好的给出推荐。
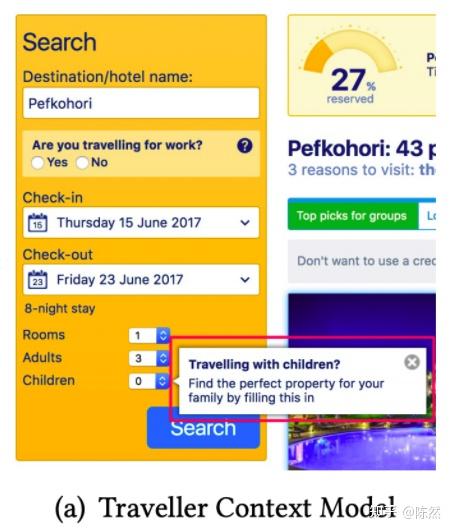
模型预测出是带了孩子旅行的,提醒选择孩子的数量
但是建模的时候,灵活度的定义可能很不同:
- 我们可以考虑这个用户跟其他用户相比,是不是会选择更多的日期
- 可以考虑用户最终确定的日期,是不是跟最早搜索的不同
- 可以预测用户到底考虑多少个不同的日期,回归模型可能更有效
- 可以预测用户到底会不会改变日期,那可能会建立一个分类模型
这个比较的过程中,我们要参考数据质量,学习的难度,Presentation Bias 的严重程度等等。
总之,不要仅仅钻进黑箱模型中只顾着提升线下几个点,而是要回归用户,想想如何建模更加合理。
线上监控很重要,也很难
一个模型上线了,我们肯定要实时地监控模型表现的好不好,这个对于线上环境来说十分重要。既然要监控,那必然需要更快速地得到 True Label 的反馈,才能看到模型的实时表现。但很多时候这个也很难,比如:
- 有些 True Label 线上并不能获取的到。比如 Booking 的例子是预测用户是否会要 Special Request,但是用户最终可能会去酒店签到的时候才要,线上无法获取。
- 有些 True Label 会延迟很久。比如预测用户是否会写反馈,用户可能要一周后才会写。
对于这些情况,Booking 给出了一种无监督的线上监控方法,只对于分类模型有效。那就是观察分类结果的分布。一个好的分类模型的结果分布应该是有两峰,并且中间相对连续的。如果分布不是这样,那大概率是模型哪里出了问题,需要排查。Booking 说这个简单的方法效果出奇的好。
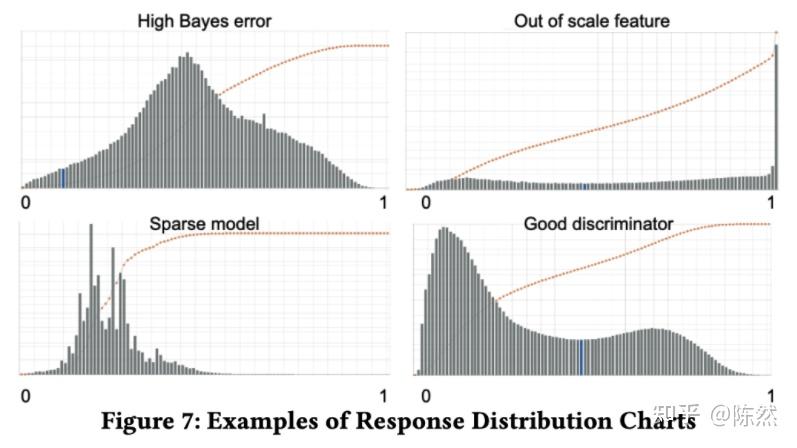
利用分类结果分布来监控模型质量
继续阅读
全部内容如何看待 Kaggle 发布的 Zillow 房价预测比赛?
谢邀 我认为这是一个非常有意思的比赛,特别是每一轮的测试集都会用实际的数据作为评判依据,依照真实买卖房价作为结果,这与以往普遍的机器学习比赛都不同,而更像金融投资比赛。这也会让更多的机器学习的爱好者多去思考千变万化毫无道理的真实世界,而不仅仅生活在理论与代码之中。 正所谓知己知彼,百战不殆,虽然作为公司内部人士,不能参...
聊聊 Tubi 的数据工程 (Data Engineering)
今天,我们的 VP 佘昶 (Chang 是大家喜爱的 Python 库 Pandas 的第二位核心作者,在 Tubi 负责数据、机器学习等业务) 发表了一篇博客: 比图科技:打造一家模型驱动型公司 - Tubi 数据与机器学习平台简介 谈到了 Tubi 的数据工程,机器学习,算法驱动。内容非常丰富,值得深入阅读。借这个...
Tubi TV是一家什么样的公司?
哈哈,看到了不少同学都提到了我们常年“招人”,这确实是 Tubi 的现状,太缺人了。 不管是国内还是美国的程序员,都不是 Tubi TV 典型的用户,所以对 Tubi 的规模其实不太了解: 我们在2019年6月宣布了两千万的月活用户[1](MAU),根据 The Verge 2019年1月的文章[2],Hulu 有两千...