I am the first Machine Learning Engineer, now what?


Tubi TV is one of the largest AVOD services, with 33 million MAU announced in 2020 and growing. Our machine learning powers tons of different applications, like ranking in the home screen, related title, search, and most popular. ML even powers essential business like ads matching, content acquisition, user acquisition, user email / push, etc. Machine Learning is everywhere, and is at the core of business and company. The goal for us is to create a model-driven enterprise.
Our ecosystem has matured a lot over time, but a lot of our most impactful lessons came in the early days. In this post, we will share some of the more practical tips we picked up along the way.
Probably you just started as the earliest member in the machine learning team and you may be asking yourself:
“What should I do now? Should I start working on the magic deep / reinforcement learning algorithm immediately?”
No, not just yet!
Measure First
While everyone loves to see things get launched, it is too early for the fancy models. And what is more important is to have a minimal working end-to-end experiment system, or A/B test system.
Why? Machine Learning algorithms can produce truly amazing results, sometimes indistinguishable from magic! However, what is an amazing experience for one user could be a truly awful one for someone else. Therefore, before putting your new algorithm in front of all users, it is paramount to get a more comprehensive understanding of how users will react to it through some type of A/B test.
Does it cost lots of resources to build a basic running A/B test system? Not really, nowadays there are tons of open source libraries and paid services that support A/B tests, you don’t have to develop everything end to end. In Tubi, the early systems are also very simple, later on we evolve to to a more matured platform.
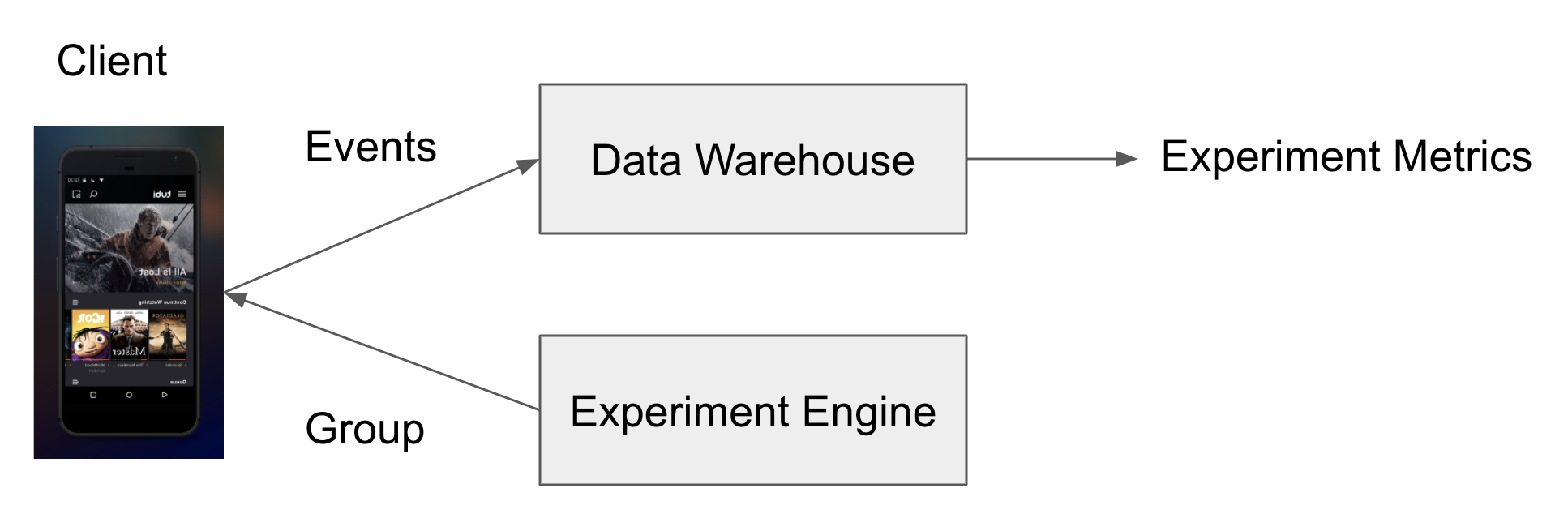
Create an action plan before the experiment starts
Having the A/B test system ready is one thing, the other important thing is about the decision making process using data. One of the most common bad practices we observe when doing experiments, is lack of an action plan before the experiment. No one can predict the future, but this is not an excuse for saying something like:
“I don’t know how it would perform, let’s just do an A/B test, see the results and then analyze.”
This is bad. By continuously doing this, you will end up with experiments having some metrics positive and some negative, and several groups of people debating which metric is more important. It could be endless and no one can move forward. This breaks the original idea of A/B test: Experiments lead to better action.
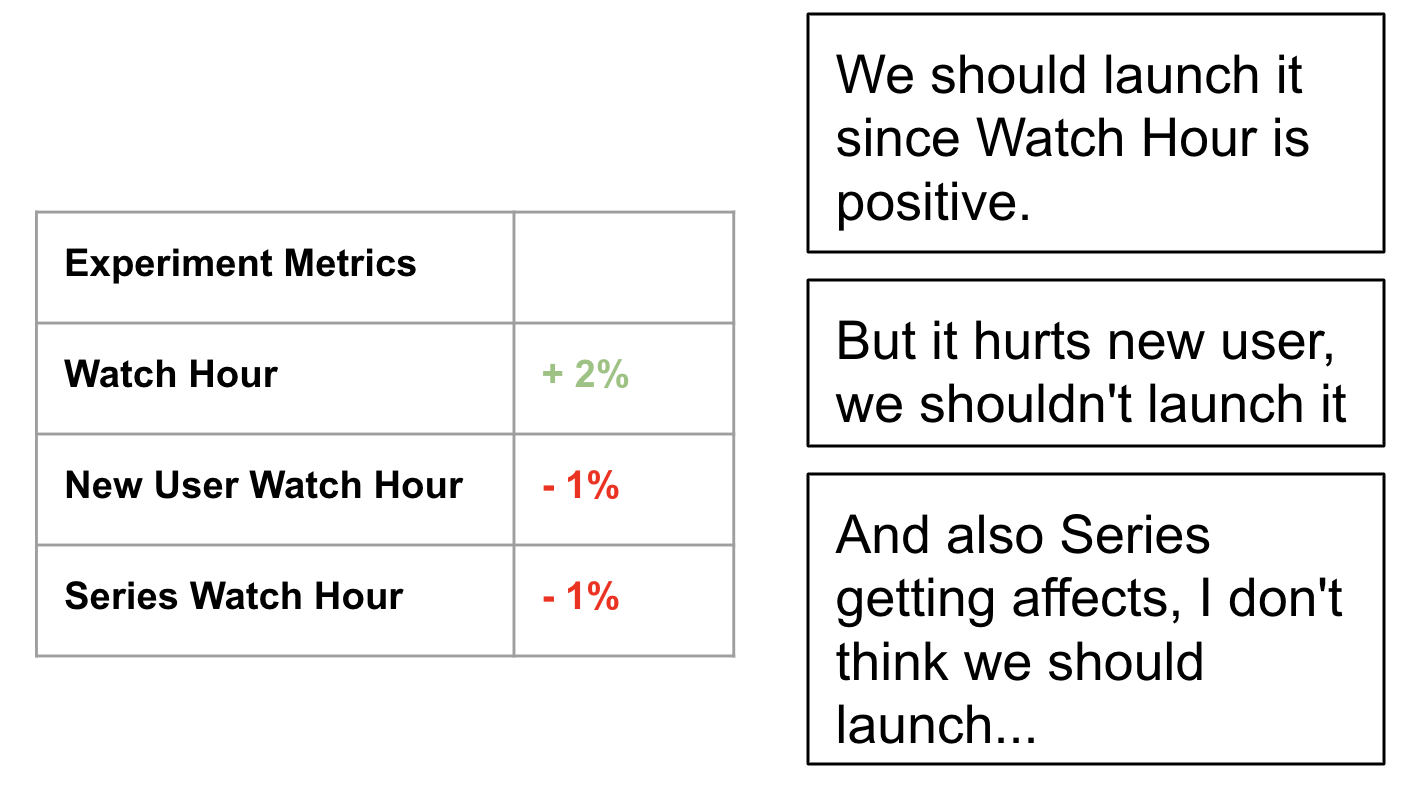
The solution for this is actually simple:
- First define one or two primary metrics for action (e.g. release it or not) and some secondary metrics for future iteration plans.
- Agree on an action plan before the experiment starts. It should be as simple as: if primary metric is positive, or primary metric is neutral but some defined secondary metrics are positive, we will launch it, otherwise no.
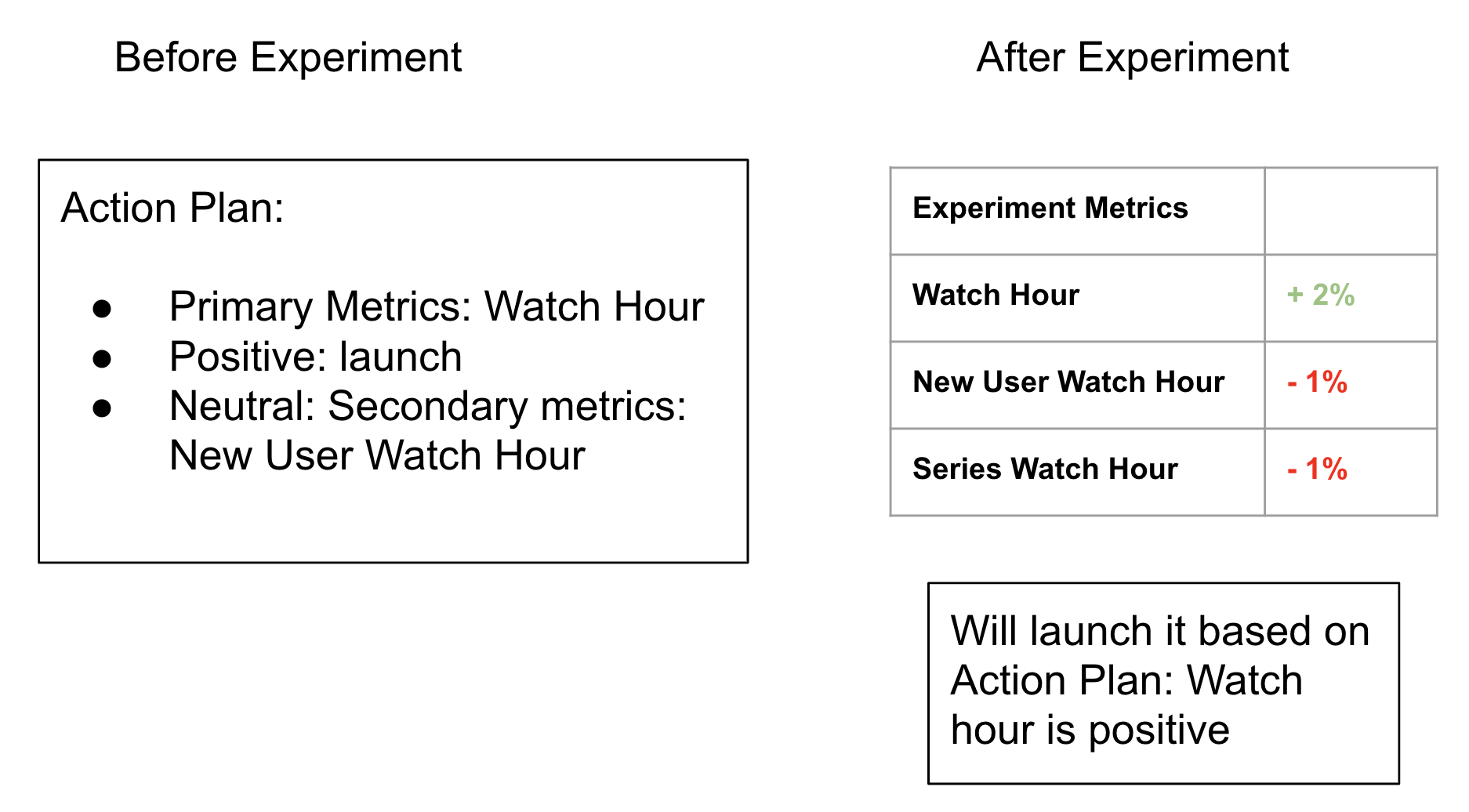
By doing this, we get some preliminary work done before the experiment even starts. After the plan is finalized, no one has to worry about the decision.
Simple models: Similarity + Popularity
So now you may be saying to yourself: “OK, I have a working framework to measure the experiment metrics, shall we start working on the complex deep / reinforcement learning algorithm?” The answer is still: “No.”
Being the first member in the team means there are also very few data / back-end engineers helping you, but there are tons of applications that need to be supported. We always think about ROI, and we need to find something easy to launch, maintain, and that will produce a good gain. Some simple models we found are super helpful at this stage.
Rank with Popularity
Ranking is everywhere. One simple method we found super powerful is to rank with popularity.
Popularity can be defined in different ways, take Tubi’s movie watching experience as an example, the easiest method is to use watch hours, like last 1 days, 3 days, 7 days watch hour for each content. We also found generally recent data is better, for example the last 1 days generally performs better than the last 7 days.
Another catch is that, the watch hour we use should be naturally generated from user, not from any promotion. We found that by removing the promotion data, popularity ranking performs better.
Embeddings Everything
The simplest ranking system is to create an embedding for every object, and calculate similarity for ranking. Take Tubi’s case as an example: Video is core in the whole ecosystem, we could build embedding for video, and then use it to represent other objects.
For example, Apache Spark ships with two robust and powerful algorithms as part of its standard library: word2vec & als (collaborative filtering), you can use user’s watch history to build video embeddings easily.
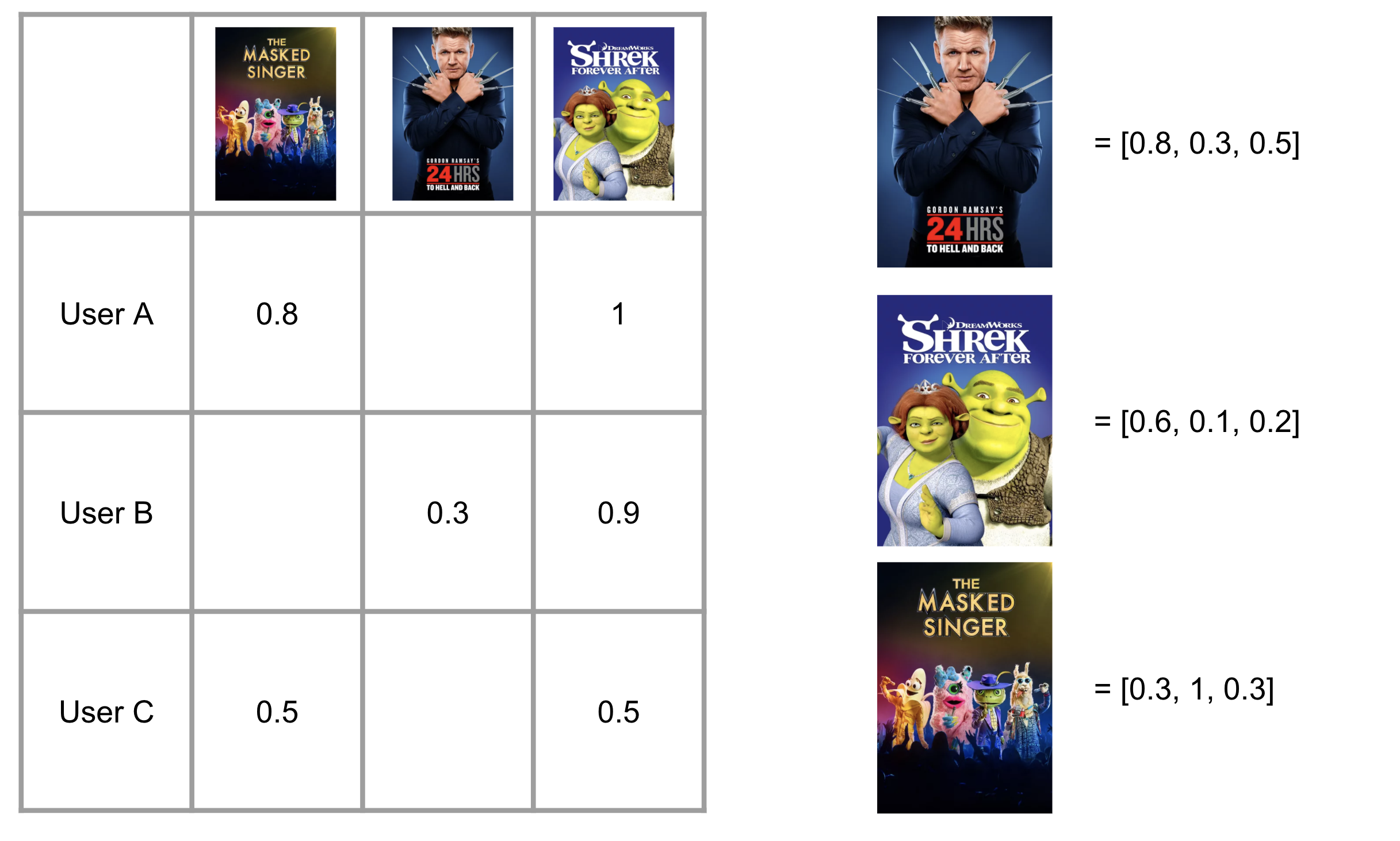
With video embedding, we could easily create other embedding:


We could keep creating embedding for user, platform, zip code, genre, etc. With every object having embedding, we could easily rank everything with scores by cosine similarity. And then apply it to different ranking problems like: user’s favorite content, platform, geo, or most similar cities, platforms, etc.
Fast iteration is key
After implementing the basic slew of algorithms, you may be naturally tempted to move on to more cutting edge techniques, such as reinforcement learning. While undergoing that same journey, we took a small detour, and instead invested some time & energy to make sure we can iterate rapidly. We found that fast iteration is key.
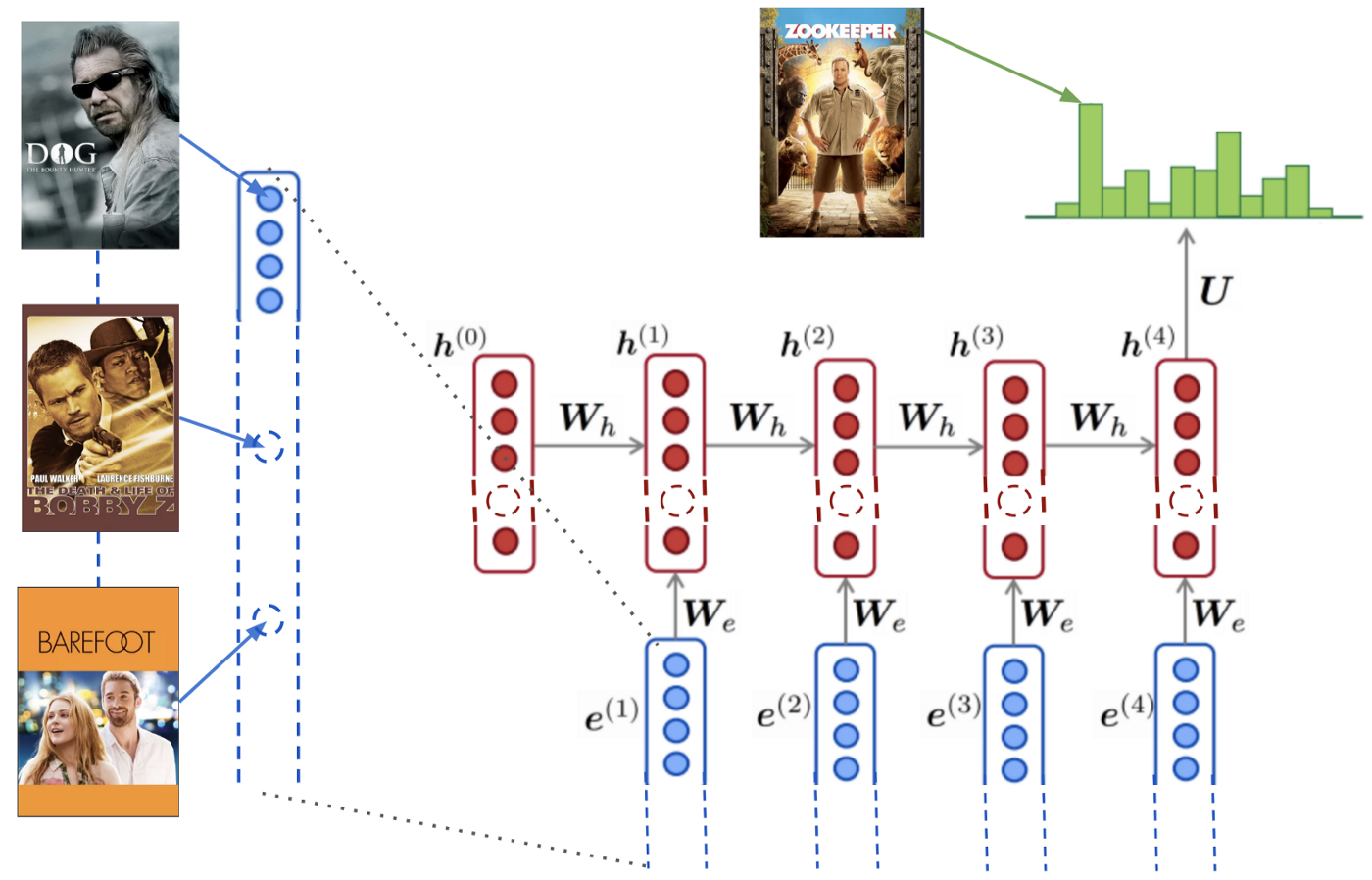
Why? In Machine learning domains there are just too many ideas and intuitions, I can easily propose dozens of directions that are worth trial: more features, deeper models, different candidate generators, different strategy for stratified sampling, multi-objective optimization, explore & exploit etc. When calculating ROI for decision making, we can easily estimate cost, but how about returns?
We can’t know the returns unless we have some prior knowledge. However, since every company has its own unique domain problems, findings from outside might not transfer easily. We need to create a simple way to accumulate hands-on findings within the company: the more the better, the faster the better.
At Tubi, we made the A/B test extremely easy to do. Our roadmap has been heavily built based on what we learned from different experiments. Even in early years we only had 2 or 3 ML Engineers working on core rankings, we could finish more than 50 experiments per year. Each experiment contains full steps from exploration, to production, to final presentation, without much need from other teams.
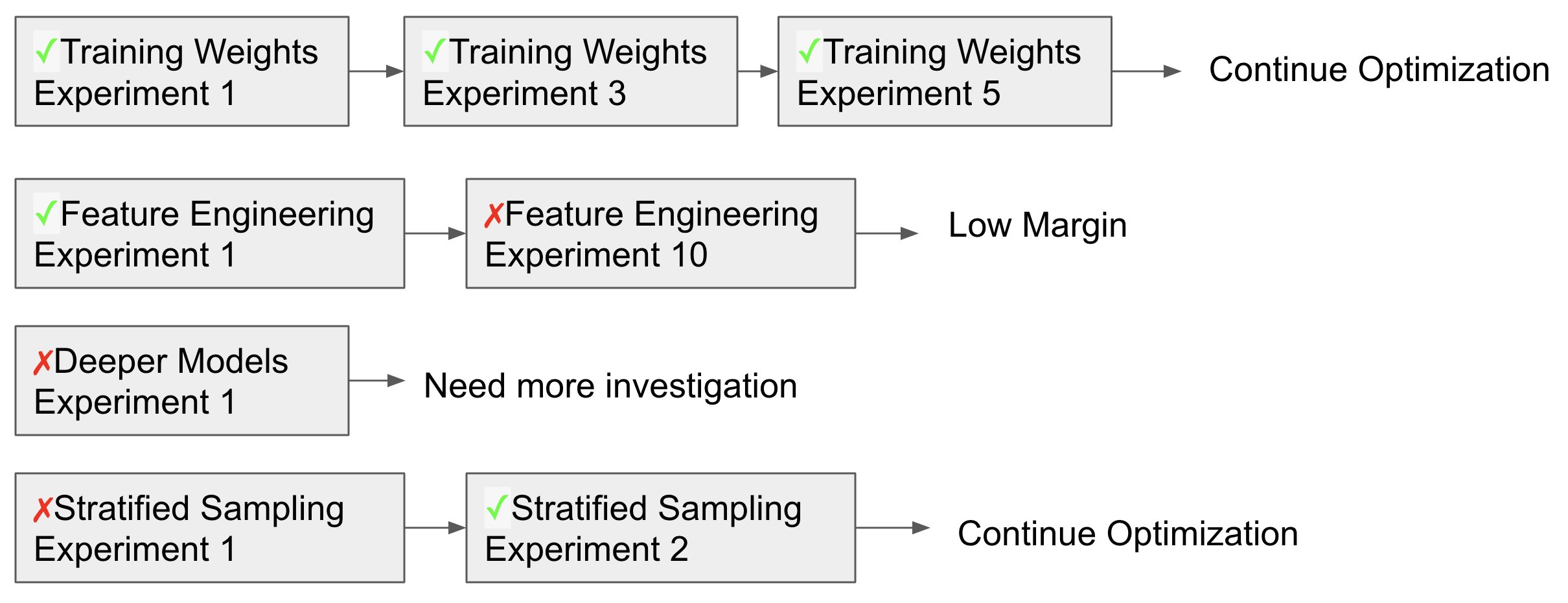
What we have learned and what is next
Over the past few years, we have accumulated a ton of experience on how to build systems designed with fast iteration of recommendation algorithms in mind. We will of course be sharing more of those learnings over time. If you are also passionate about experiment driven machine learning, we are actively hiring, join us!
继续阅读
全部内容机器学习团队领导艺术:技术、管理与业务的平衡之道
引言 在人工智能时代,机器学习团队的管理具有独特的复杂性。与传统软件团队不同,机器学习团队往往汇聚了算法研究、数据工程和业务应用等多学科人才 (Author Q&A: Effective Machine Learning Teams | Thoughtworks United States)。团队需要跟进行业最新研究进...
大模型落地的未来:开源+微调?
最近,AI 社区里流传着这样一句话——“通用大模型很强,但我并不需要我的应用去给我背诵法文诗歌。” 这句话听上去有点调侃,却反映了一个重要现象:许多企业和开发者在早期会选择大型通用模型(例如 GPT-4)去快速验证想法,但真正想要落地到生产环境,往往发现必须在速度、成本和“专用领域准确度”之间做权衡。 于是,“微调(F...
谁来颠覆低频刚需?
这篇文章是我2017年写的草稿但一直没有发布,那时候 Google 刚刚提到 AI First 的战略,互联网的迭代重点还是以推荐系统和深度学习为核心。时至今日 LLM 的出现让这个问题有了些许答案,想了想还是把文章发布出来。 推荐系统的胜利 过去五年,机器学习在推荐系统领域的研究,给高科技企业带来了巨大的收益。我们在...